SCANimate: Weakly Supervised Learning of
Skinned Clothed Avatar Networks
Shunsuke Saito, Jinlong Yang, Qianli Ma, and Michael J. Black
CVPR 2021 (Oral, best paper candidate)
[Animations] [Highlights] [Video] [CVPR talk]
[Paper] [Poster] [Code]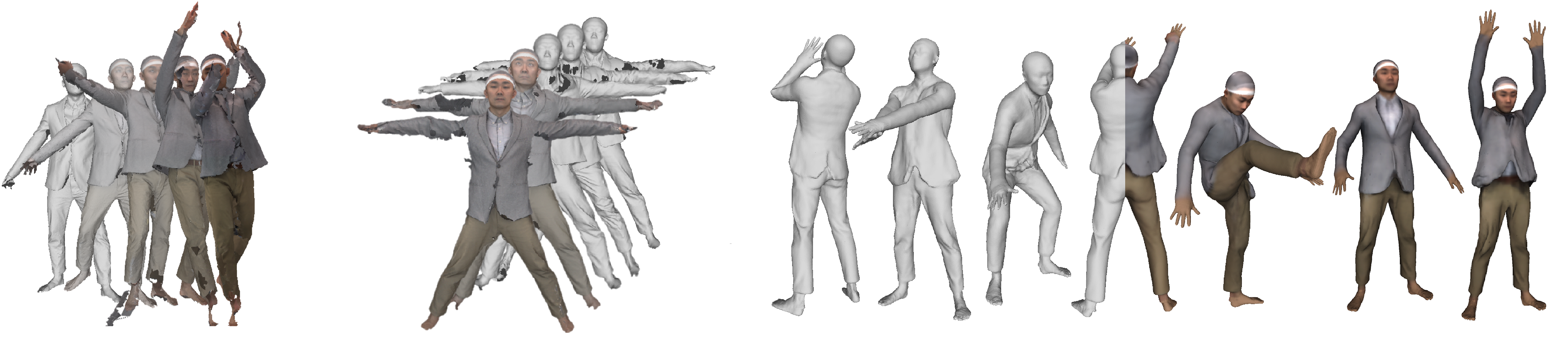
We create an avatar with pose-dependent clothing deformation from raw scans without template surface registration.
Abstract
We present SCANimate, an end-to-end trainable framework that takes raw 3D scans of a clothed human and turns them into an animatable avatar. These avatars are driven by pose parameters and have realistic clothing that moves and deforms naturally. SCANimate does not rely on a customized mesh template or surface mesh registration. We observe that fitting a parametric 3D body model, like SMPL, to a clothed human scan is tractable while surface registration of the body topology to the scan is often not, because clothing can deviate significantly from the body shape. We also observe that articulated transformations are invertible, resulting in geometric cycle-consistency in the posed and unposed shapes. These observations lead us to a weakly supervised learning method that aligns scans into a canonical pose by disentangling articulated deformations without template-based surface registration. Furthermore, to complete missing regions in the aligned scans while modeling pose-dependent deformations, we introduce a locally pose-aware implicit function that learns to complete and model geometry with learned pose correctives. In contrast to commonly used global pose embeddings, our local pose conditioning significantly reduces long-range spurious correlations and improves generalization to unseen poses, especially when training data is limited. Our method can be applied to pose- aware appearance modeling to generate a fully textured avatar. We demonstrate our approach on various clothing types with different amounts of training data, outperforming existing solutions and other variants in terms of fidelity and generality in every setting.
Learned Scanimats animated by motions from AIST++


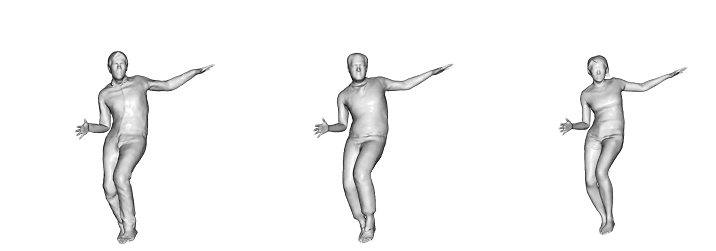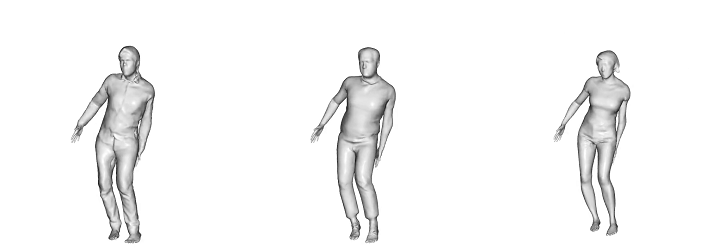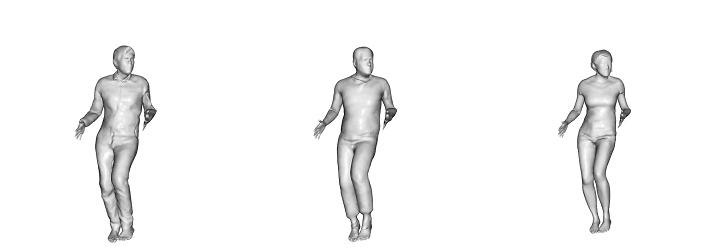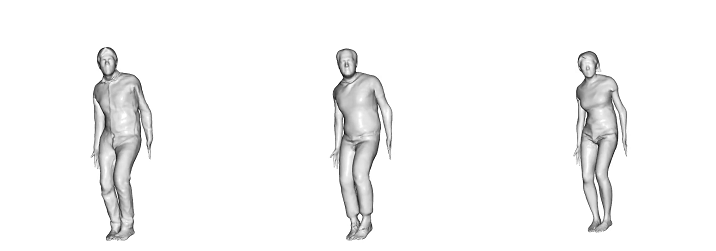
Learned Scanimats animated by motions from AMASS



- Extending linear blend skinning to 3D space.
To align all the scans to a common canonical pose, we extend traditional surface linear blend skinning to 3D space represented by neural networks with learnable parameters, focusing on body and clothing surfaces.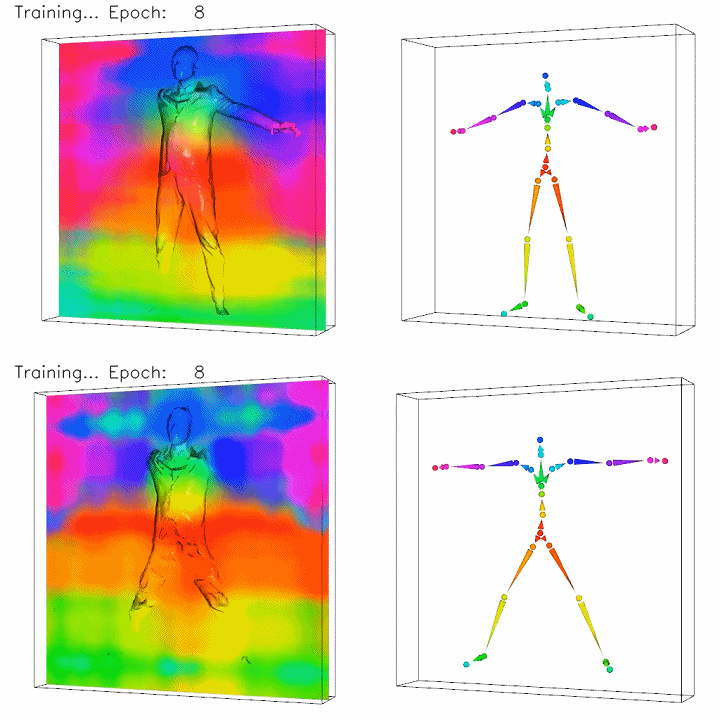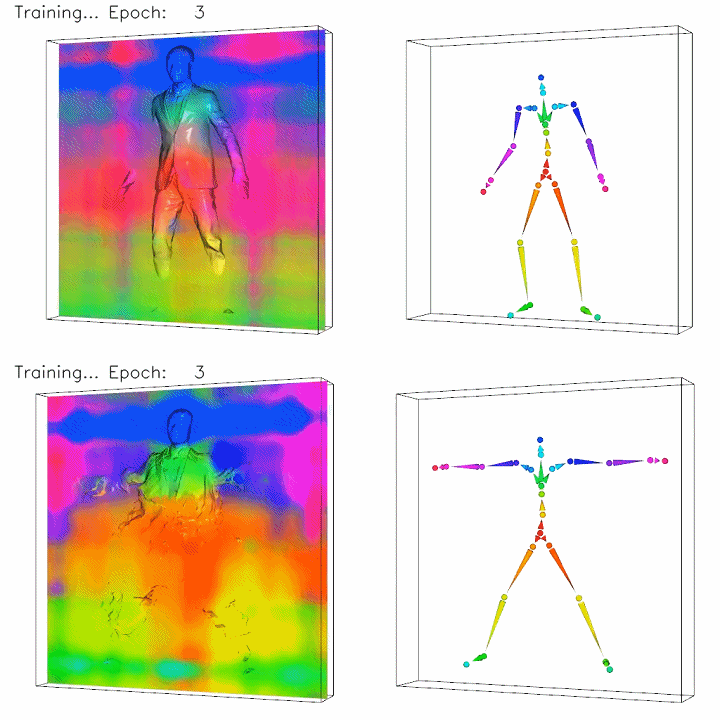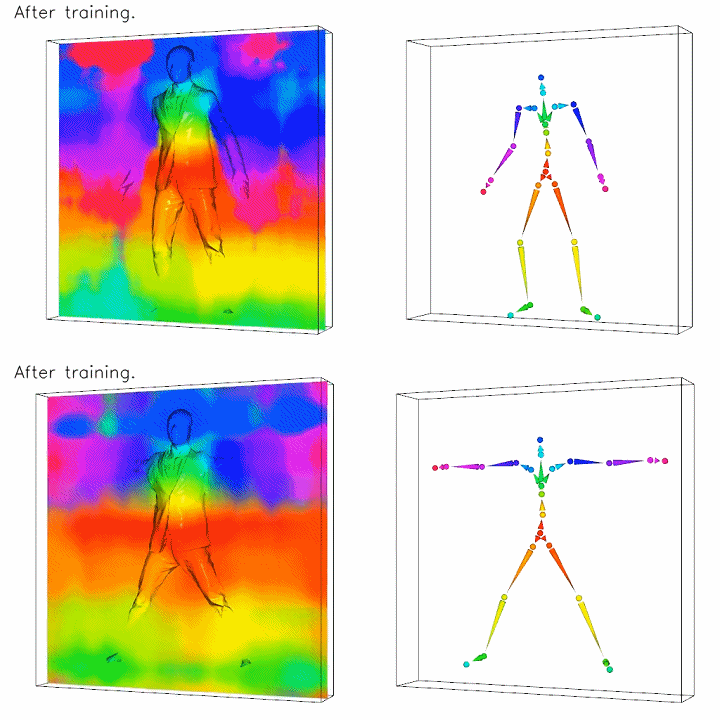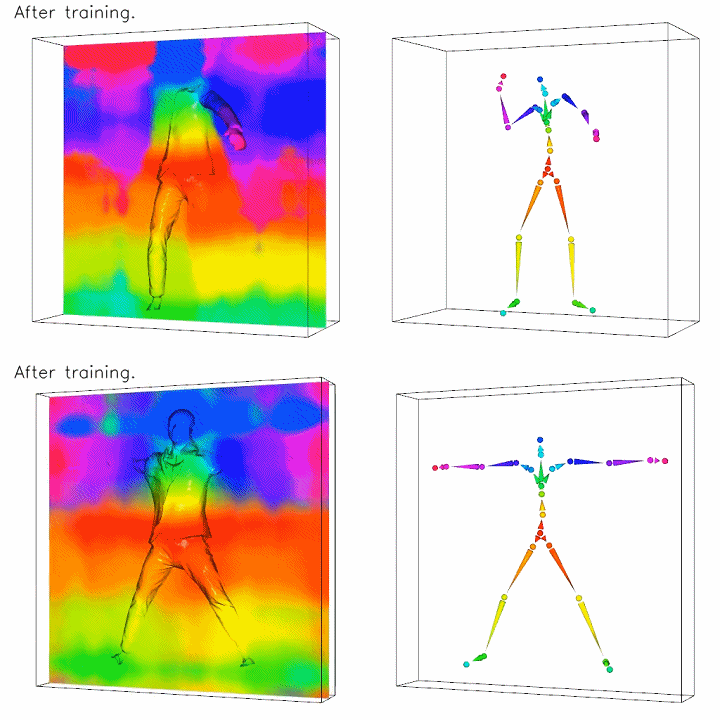
Top: posed space. Bottom: canonical space. The color on the left column images indicates the skinning weights to the bone with the corresponding color on the right columns. Note how the unknown canonical clothing geometry is optimized in the bottom left image.
- Cycle consistency.
The spatial skinning weights are optimized by enforcing the cycle consistency over posed and canonical space.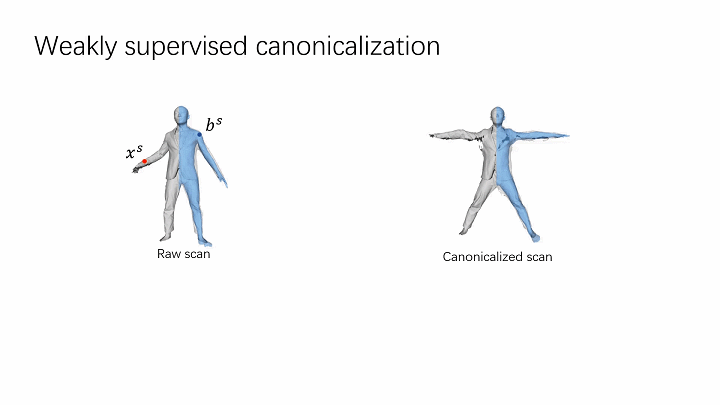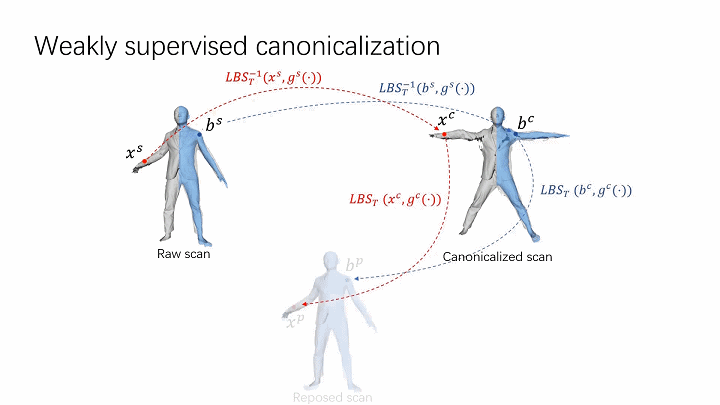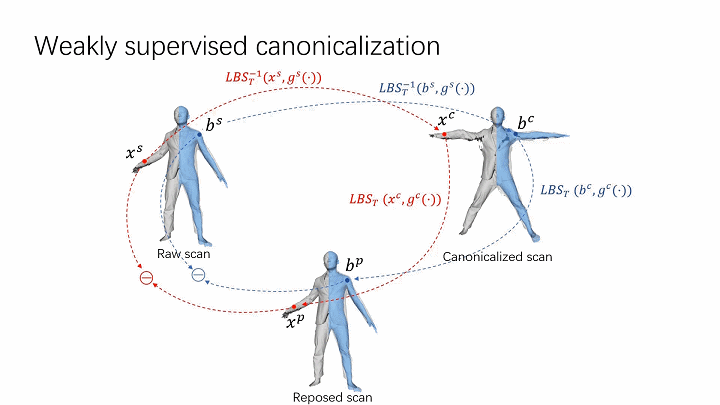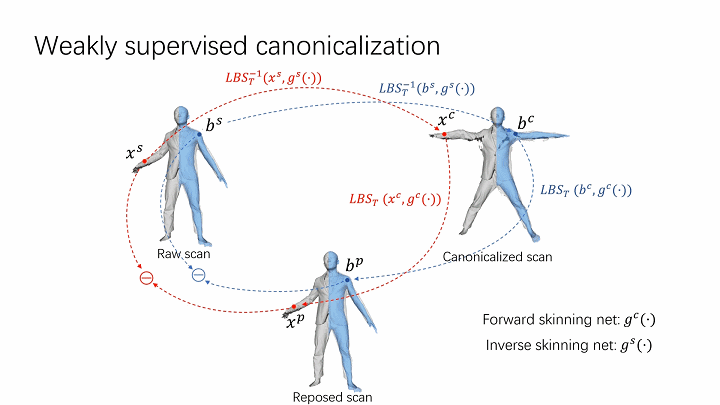 The skinning weights on the body surface that are provided by the fitted body model (SMPL) are used to provide weak supervision to optimize both forward and inverse skinning nets. The cycle consistency over posed and canonical space provides effective regularization to learn volumetric skinning weights.
The skinning weights on the body surface that are provided by the fitted body model (SMPL) are used to provide weak supervision to optimize both forward and inverse skinning nets. The cycle consistency over posed and canonical space provides effective regularization to learn volumetric skinning weights. - Local pose-aware shape modeling.
To address the common spurious correlation between pose-dependent clothing shapes and global pose parameters, we condition local shape on local pose information.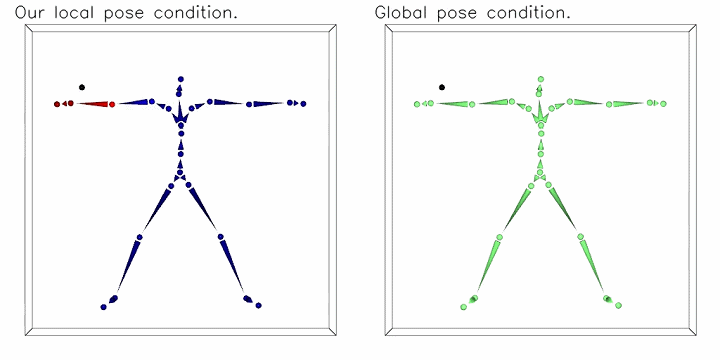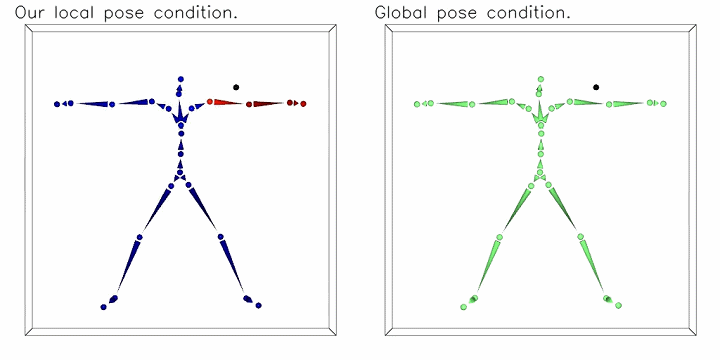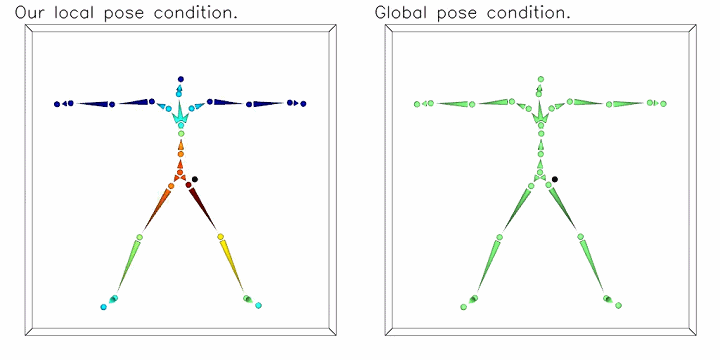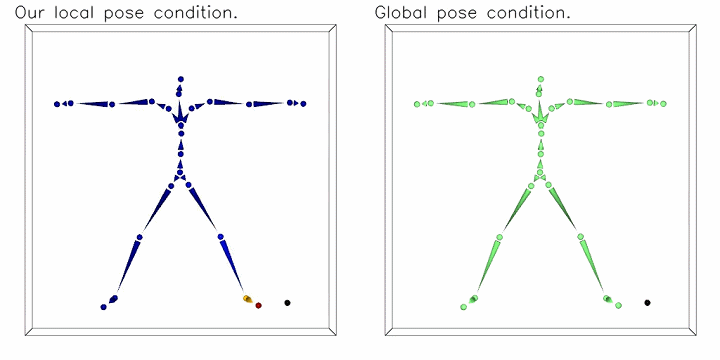 The moving black dot is the 3D query point for neural implicit shape. Instead of using equally weighted global pose as conditions (the figure on the right), we propose to weight joint parameters according to the LBS weights predicted at the query position and the kinematic chain (as shown on the left figure, color indicating weights).
The moving black dot is the 3D query point for neural implicit shape. Instead of using equally weighted global pose as conditions (the figure on the right), we propose to weight joint parameters according to the LBS weights predicted at the query position and the kinematic chain (as shown on the left figure, color indicating weights).
(If the Youtube video does not play, click here to view the video.)
CVPR talk
(If the Youtube video does not play, click here to view the video.)
Paper

SCANimate: Weakly Supervised Learning of Skinned Clothed Avatar Networks
S. Saito, J. Yang, Q. Ma, M. J. Black.
CVPR 2021 (Oral Presentation)
[PDF] [Supp] [arXiv]
BibTex
@inproceedings{Saito:CVPR:2021,
title = {{SCANimate}: Weakly Supervised Learning of Skinned Clothed Avatar Networks},
author = {Saito, Shunsuke and Yang, Jinlong and Ma, Qianli and Black, Michael J.},
booktitle = {Proceedings IEEE/CVF Conf.~on Computer Vision and Pattern Recognition (CVPR)},
month = jun,
year = {2021},
month_numeric = {6}}
Related Projects
SCALE: Modeling Clothed Humans with a Surface Codec of Articulated Local Elements (CVPR 2021)
Qianli Ma, Shunsuke Saito, Jinlong Yang, Siyu Tang, Michael J. Black
Modeling pose-dependent shapes of clothed humans explicitly with hundreds of articulated surface elements: the clothing deforms naturally even in the presence of topological change!
Learning to Dress 3D People in Generative Clothing (CVPR 2020)
Qianli Ma, Jinlong Yang, Anurag Ranjan, Sergi Pujades, Gerard Pons-Moll, Siyu Tang, Michael J. Black
CAPE — a generative model and a large-scale dataset for 3D clothed human meshes in varied poses and garment types. We trained SCANimate using the CAPE dataset. The raw scan data of the subject in a blazer jacket (see our teaser figure) is now available at CAPE website upon request. Check it out!